

Parasuraman’s Automation Ladder
Clinical Practice can learn quite a bit from aviation

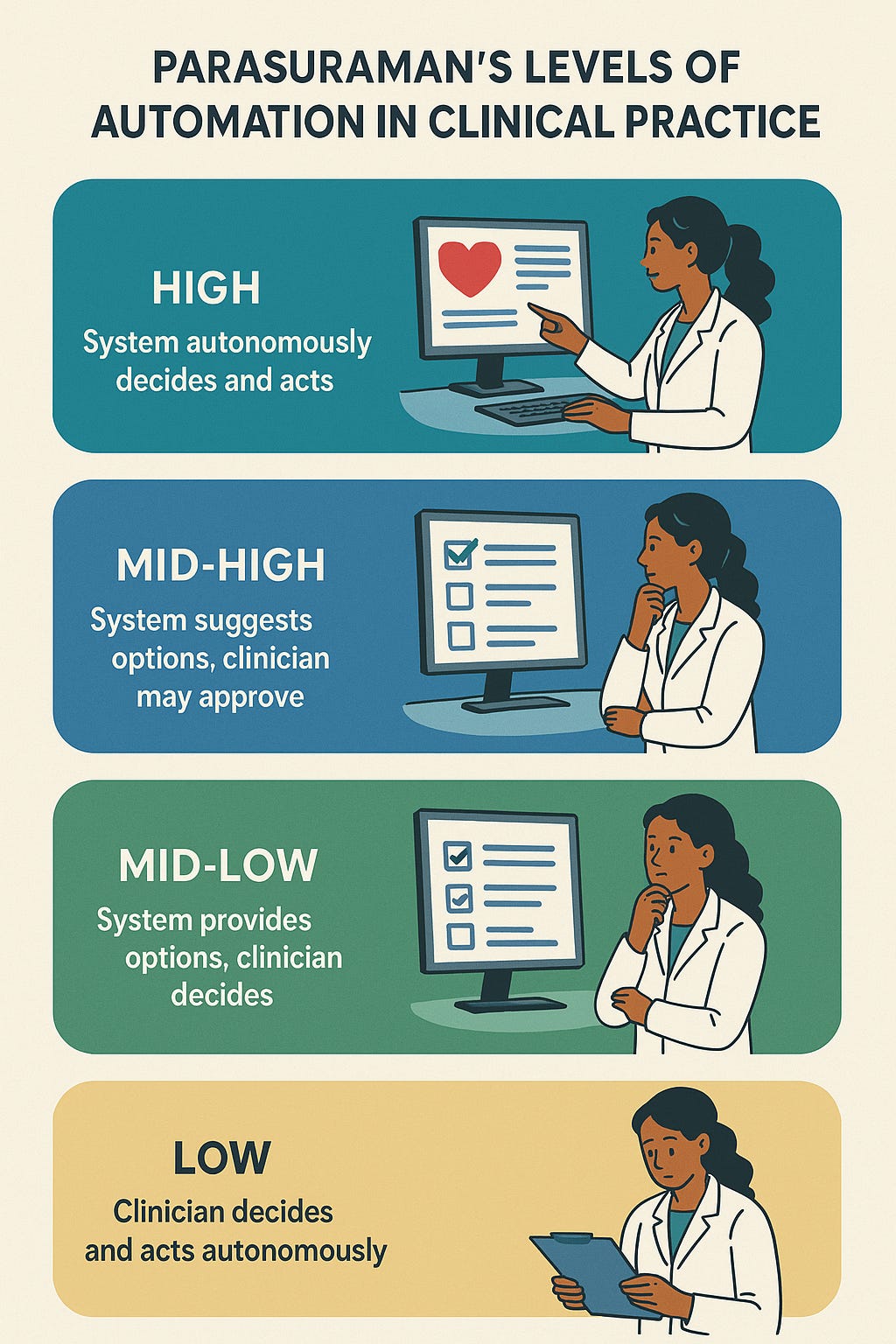
A bit different than our usual area as I wanted to bring in my learnings of integrating AI into my clinical practice, something that converges our two favorite topics. Clinical innovation and aviation. As a self-professed AvGeek Parasuraman’s Automation Ladder forms the cornerstone of aviation efficiency. In the decades leading up to their 2000 paper, P…
